Type “what is machine learning” into Google, Bing, Yandex, or any other search engine, and you’ll find more than a billion articles, opinions, blog posts, and forums on this critical term. Machine learning has become one of the most used approaches in data science. It has also joined the ranks of most overused words in business jargon.
Machine learning is used in a wide range of applications such as web search, spam filters, recommender systems at Netflix or Amazon, advertisement placement, credit scoring, fraud detection, stock trading, drug design, and so many other applications.
Despite its extensive use, machine learning is still not well understood by many business leaders. And so many still ask “what is machine learning?”
The purpose of this article is first to offer a definition of machine learning for an executive. The rest of the report provides a thorough overview on use cases, most recent developments as well as machine learning’s limitations.
In developing a working definition of machine learning, we rely on what other machine learning experts, researchers think, and synthesize their views into an easy to remember definition of machine learning (ML) that other business leaders might find useful.
“Google’s self-driving cars and robots get a lot of press, but the company’s real future is in machine learning, the technology that enables computers to get smarter and more personal.”
ERIC SCHMIDT (GOOGLE CHAIRMAN)
The best approach to derive a working definition of machine learning is by providing an in-depth overview of the fundamentals of ML. Understanding the strengths and the promise of machine learning is undoubtedly exciting.
You might have heard about the advances in deep learning, which we cover in this article briefly. Deep Learning is actually a subset of machine learning and has evolved tremendously over the last ten years allowing us to make progress over applications such as self-driving cars, natural language, computer vision.
We’ve also come to learn that machine learning has limitations. In this article, we will discuss ML’s limitations and challenges.
Finally, we’re discovering that getting machines to think is not merely a computer science problem. Getting machines and robots to think and act and make choices such as driving a car safely and making tough business choices requires us to consider and tackle a host of disciplines above and beyond programming.
We reviewed many definitions of ML before we synthesized them to a simple one that we believe will resonate with executives and non-technical business leaders. Here is our answer to “what is machine learning”:
Our definition: Machine Learning is a field of computer science that aims to get computers to observe, learn, and gain experience on their own so that they can make choices that we, humans, would consider intelligent.
We prefer this definition for multiple reasons. One, this definition of machine learning doesn’t include jargon or any technical terms. It’s quite easy to remember.
More importantly, it captures the essence of artificial intelligence. Remember that the field of artificial intelligence has started initially from our desire to build autonomous intelligent machines that can perform at human or superhuman levels. This definition of machine learning encapsulates this desire.
Finally, the above definition of ML focuses on making choices, because ultimately, it’s not about observing and learning that makes these machines intelligent. It’s about their ability to make the right choices within a business context, or a real-world situation, such as recommending the right product or navigating a car without causing an accident.
There is no consensus among machine learning practitioners on a well-accepted definition of what machine learning is.
The following represent how artificial intelligence scientists have defined machine learning in various ways.
One of the fathers of machine learning was Arthur Samuel. He was an American ML pioneer and professor of electrical engineering who developed an approach that is used in Artificial Intelligence even today: using games to facilitate self-learning. Arthur Samuel wrote the first self-learning algorithm that learned to play checkers, a board game much simpler than chess or the ancient board game Go and beat champions. He also popularized the term machine learning in 1959.
Here is how Arthur Samuel defined ML:
“Machine learning is the field of study that gives computers the ability to learn without being explicitly programmed.” ARTHUR SAMUEL
“Machine learning is based on algorithms that can learn from data without relying on rules-based programming”
MCKINSEY
“Machine learning is a field of computer science that aims to teach computers how to learn and act without being explicitly programmed. More specifically, machine learning is an approach to data analysis that involves building and adapting models, which allow programs to “learn” through experience.”
DEEPAI
“Machine learning is a type of artificial intelligence (AI) that enables computers to learn automatically without being explicitly programmed. It focuses on the development of computer programs that can access data and use it to learn for themselves.”
FERMILAB
According to Tom Mitchell, professor of Computer Science and Machine Learning at Carnegie Mellon, “a computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.”
Another way of saying the above is that “a program uses ML if it improves its problem-solving skills with experience.”
One final definition that we decided to include here also comes from Tom M. Mitchell, Interim Dean at the School of Computer Science at CMU, Professor and Former Chair of the Machine Learning Department at Carnegie Mellon University.
“A scientific field is best defined by the central question it studies. The field of Machine Learning seeks to answer the question: “How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes?”
TOM M. MITCHELL
As you can see, there are many ways to define ML. Regardless of how you define it, it’s essential to understand where and when machine learning should be used.
As with anything else, machine learning is not appropriate to apply to every type of problem. There are many cases where a solution can be developed without using ML. For example, you don’t need to rely on ML if you can simply program a computer with predetermined steps and rules and calculations to conduct several simple or straightforward tasks.
Again, you are better off not utilizing ML if there is not much data available. At the same time, there are cases when machine learning is appropriate, suitable, and more effective vs. a deterministic, rule-based approach.
Here are four examples of when to use machine learning:
Use machine learning when it’s difficult to code the rules: Many tasks that humans perform are quite complex. Consider driving a car by way of example. In itself, driving consists of a few simple tasks; the critical decisions that we make while driving are quite a few. At any given time during driving, we may decide to drive forward or backward. We may decelerate, accelerate, or maintain speed. And we may adjust towards right or left. However, if you try to write a rule-based program that seeks to encompass all the possible scenarios in real-time, you will immediately find out that there are too many factors to consider, and that these rules overlap with each other to the extent it’s extremely difficult to impossible for anyone to code all the rules. This is a perfect example where machine learning, ML, can be applied effectively to solve this problem.
Use machine learning when it’s challenging to scale the task: There are many tasks that we do every day. Looking at emails is one of them. When we read an email that we consider spam, it takes us a few seconds to identify that and categorize the email as spam. If we didn’t have spam filters, which are machine learning algorithms that, over time, learn and improve, we would collectively spend millions of hours just to detect and erase spam emails, in itself a very tedious task. This is a perfect opportunity to apply machine learning because ML can be scaled much faster once it’s up and running.
Use machine learning when dealing with large databases: Humans are not very good at digesting large volumes of information. Humans can’t process millions of user interaction data or medical records stored in large databases. Machine learning is applied to mine these databases and make sense of the data. Furthermore, machine learning algorithms predict based on what they learn from structured, unstructured data, and inferences.
Use machine learning when building self-improving systems: Over the last ten years, we’ve developed many applications that rely on experience. Consider Netflix or Amazon’s recommendation engines. These are machine learning algorithms that learn over time and across user interfaces. Self-improving systems such as the above are perfect use cases for machine learning that companies should use.
Now that we have reviewed a list of suitable areas for when to use machine learning, in this section, we’re going to explore a few basic concepts in machine learning.
The idea behind machine learning is not complicated. The objective is to use a training data set that is large enough so that we can train a learning algorithm to get “smart” about this data set and what it represents. And when presented with a new input, the learning algorithm will be able to predict an output that is “intelligent.”
An example of a training set could be any data set that connects an output to an input. For example, historical sales prices of houses and their associated features such as square footage, number of rooms make a good training set to train an algorithm. The idea would be that if we were to train the model, it could learn how to accurately predict the selling price as a function of the house’s features, we should be able to price a new house quite easily.
That’s precisely what Zillow does. If you’re familiar with Zillow, the US real estate technology company has more than a hundred million listings in the US and developed a value estimator called Zestimate. Zestimate is based on a proprietary algorithm. Zillow uses artificial intelligence to boost the accuracy of its home-valuation software. The company claims that Zestimate gets within 5 percent of the sales price nearly 84 percent of the time and within 10 percent, more than 95 percent of the time.
Zestimate is not new; it was introduced in 2006 but has gone through numerous iterations. The company awarded $1 million in 2019 for Zillow Prize, the company’s competition to improve the accuracy of Zestimate. According to Zillow, the winning team created an algorithm that’s 13 percent more accurate than Zillow’s current model. The team utilized deep neural networks to directly estimate home values and remove outlier data points that fed into their algorithm.
As the Zillow example shows, machine learning can be categorized based on function (e.g., regression, decision tree, clustering, classification, deep learning) or the learning style employed (e.g., supervised learning, unsupervised learning, semi-supervised learning).
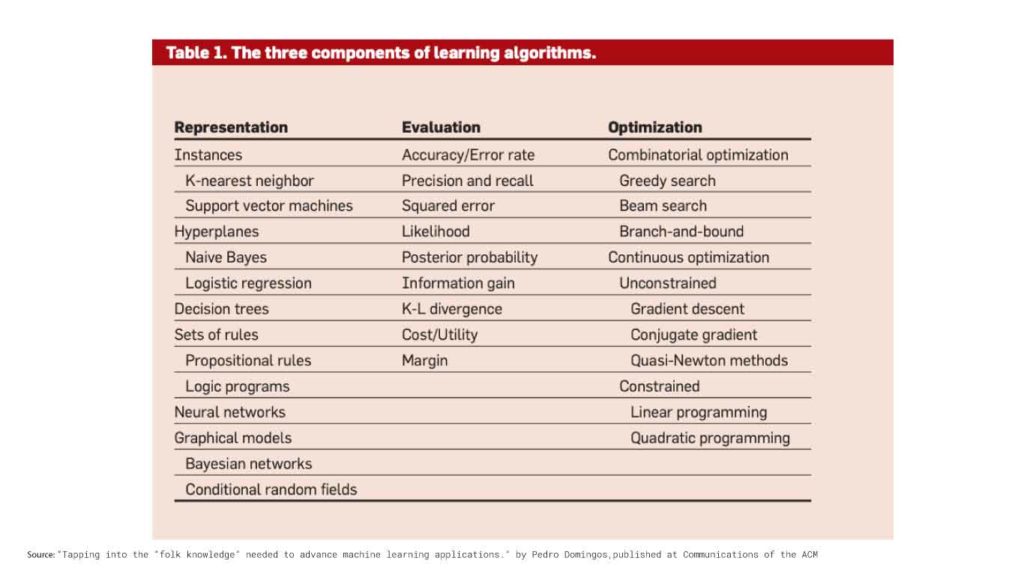
According to Pedro Domingos, a professor at the Department of Computer Science and Engineering at the University of Washington, regardless of learning style or method used, all machine learning algorithms consist of three key components:
Learning = Representation + Evaluation + Optimization
It’s easy to get lost in the sea of literally thousands of machine learning algorithms available today, but when one thinks about the problem space as Domingos suggests, it becomes easier.
Representation means that you need to bring your data into a form that is suitable for the algorithm to understand. If you’re working with text, you will need to extract features from your documents (input data) and bring them into a form that the machine can interpret.
“Choosing a representation for a learner is tantamount to choosing the set of classifiers that it can possibly learn. This set is called the hypothesis space of the learner,”
PEDRO DOMINGOS
Evaluation: Evaluation function is used to differentiate between good and bad classifiers. Domingos points out to the fact that the optimization function that the algorithm uses may be different than the overall objective function.
Optimization: We need a method to search among the classifiers for the highest-scoring one. The choice of optimization technique is key to the efficiency of the learner, and also helps determine the classifier produced if the evaluation function has more than one optimum. It is common for new learners to start out using off-the-shelf optimizers, which are later replaced by custom-designed ones.
In supervised learning, we have a data set with input and output parameters. They are labeled, so we know what we’re looking at. We also know what our correct output should look like based on the input data. That means, in supervised learning, there is a relationship between the input and the output. For example, a data set might be an inventory of used cars and their selling prices. You can build an algorithm that learns from past sales and identifies the relationship between price and several features (e.g., mileage, brand, accident history, ZIP code). Because the output of this algorithm will be a numeric value – in this case, the estimated selling price – it can be solved using a regression analysis.
If you had a data set that had tumor sizes and ages of patients and the central question that you were trying to answer was to identify whether or not you could determine whether a patient with specific tumor size is more likely to develop a malignant tumor or not, this would have been a classification problem. While in regression, you have a continuous output, in classification problems, the output is discrete, YES or NO, or one or zero.
Some examples of Supervised Learning are Regression, Decision Tree, Random Forest, KNN, Logistic Regression.

Supervised vs. Unsupervised Learning
Unsupervised Learning provides a learning setting where we give the algorithm a large amount of data and ask it to find structure in it. The algorithm will analyze the data set and find clusters in it, identifying similarities and inherent characteristics of data that one might otherwise miss. Unsupervised learning allows us to approach problems where we might have very little or no idea what our results should look like to get an understanding of interrelationships in the data. Using Unsupervised learning, we can potentially derive structure from data where we don’t necessarily know the effect of the underlying variables.
If we were given millions of different genes of actual humans and were asked to group these based on similarities and anomalies, we would turn to unsupervised learning to help us start understanding this dataset and clustering the data.
The figure above explains the difference in how supervised learning works in comparison to unsupervised learning. Let’s assume that we are trying to build a predictive model that can identify a car in a picture. In supervised learning, we would feed the algorithm with a large data set consisting of images of vehicles, as well as photos of bikes, fish, and so forth. The data would be labeled helping the algorithm to know whether or not it’s looking at a picture of a car or not. The machine learning model, or predictive model, would look at each picture and identify common patterns of vehicles. Over time and with the help of a large data set, the predictive model learns to determine what a car looks like. And so, when the predictive model is presented with a picture of a fish, it would be able to identify that this picture is not a car.
In the case of unsupervised learning, the algorithm would be fed with a large data set of pictures of cars and non-cars without any labels. The algorithm would focus on identifying features and patterns among these pictures that make them look alike and cluster them based on patterns.
Examples of Unsupervised Learning are the Apriori algorithm and K-means.
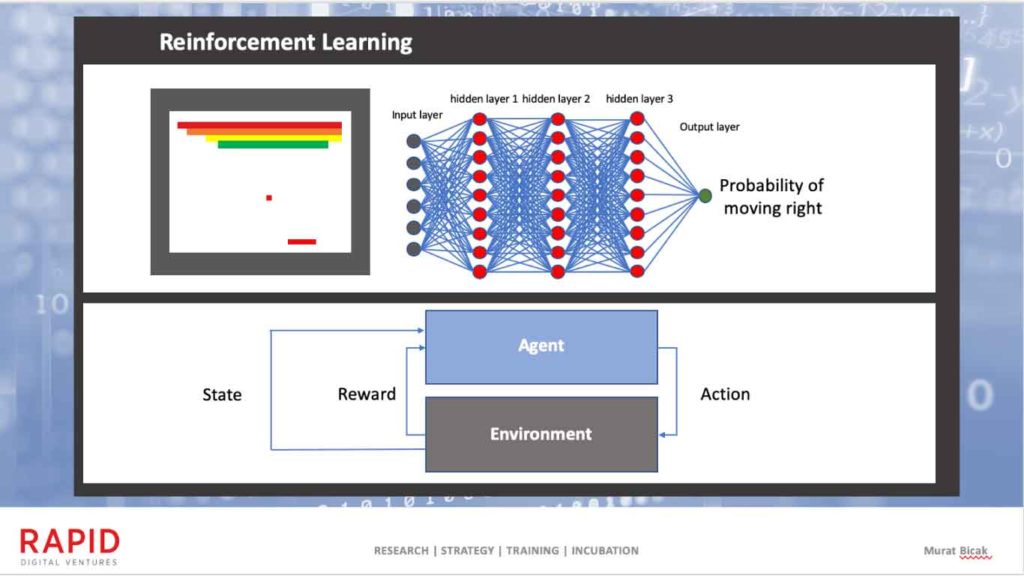
Reinforcement learning is the third category of learning model in which the algorithm is trained to achieve a goal in an uncertain, potentially complex environment.
In reinforcement learning, a game-like situation is created, and the machine gets rewarded or penalized based on the actions it performs. As a result, the algorithm employs trial and error to come up with a solution to the problem, while it’s trying to maximize the total reward.
An example of Reinforcement Learning
The designer sets the reward policy but does not offer information on how to solve the game. It’s up to the model to figure out how to perform the task to maximize the reward, starting from totally random trials and finishing with sophisticated tactics and superhuman skills. By leveraging the power of search and many tests, reinforcement learning is currently the most effective way to hint the machine’s creativity.
The key distinguishing factor of reinforcement learning is how the agent is trained. Instead of inspecting a data set that is provided, the model interacts with the environment and generates a data set that way, seeking ways to maximize the reward. In the case of deep reinforcement learning, a neural network is in charge of storing the experiences and thus improves the way the task is performed.
In contrast to human beings, artificial intelligence systems can gather experience from thousands of parallel gameplays if a reinforcement learning algorithm is run on a sufficiently robust computer infrastructure.
An example of Reinforcement Learning is Markov Decision Process.
Different types of machine learning algorithms have been put to use in data science. The following is a list of the most commonly used algorithms. These algorithms can be applied to almost any data problem. An in-depth exploration of these algorithms is outside of the scope of this article; therefore, we are only going to provide a simple list below.
The idea of trusting data and algorithms has its advantages and disadvantages. There is no question that algorithms have tremendous power, but there has moments where we found out that merely relying on them without questioning can be very risky.
The most commonly discussed case is in the domain of autonomous vehicles; how do we choose how the car should react in the event of selecting between hitting someone on the side of the road or potentially harming the life of its rider? Who’s life is more valuable, and how will the machine make that choice? Who is to blame when the car hits a person on the street? These are very valid questions for which there is no simple answer.
“Poor data quality is enemy number one to the widespread, profitable use of machine learning.” wrote Thomas Redman in article published at HBR in 2018.
It’s not just historical training data that must meet broad and high-quality standards. The data must be correct and properly labeled. But it also has to be the right data — unbiased data, representative over a range of inputs.
“Machine learning can’t get something from nothing…what it does is get more from less.” – Dr. Pedro Domingo, University of Washington
Machine learning has shown promise in enabling self-driving, making advances in radiography, and predicting our interests based upon past behavior. But with the benefits of machine learning, there are also significant challenges. One critical problem is the potential presence of bias in the classifications and predictions of machine learning.
These biases have consequences based upon the decisions resulting from a machine learning model. Therefore, it’s essential to understand how bias can be introduced into machine learning models, how to test for it, and how then how to remove it.
Machine learning is a critical tool in human resources in a variety of use cases — from training to recruiting. In 2014, Amazon began developing a system to screen job applicants to automate the process of identifying applicants to pursue based on the text on their resumes. But what Amazon found was that the algorithm appeared to favor men over women in engineering roles. Amazon abandoned the system after discovering that it wasn’t fair after multiple attempts to instill fairness into the algorithm.
The Google Photos application can be used to categorize pictures by identifying objects within them. But in 2015, a black software developer embarrassed Google by tweeting that the company’s Photos service had labeled photos of him as a “gorilla.” Google declared itself “appalled and genuinely sorry.”
As demonstrated in this paper, machine learning has revolutionized the world in the past decade. The explosion of available user information on the internet has resulted in the collection of massive amounts of data, especially by large companies such as Facebook and Google. This amount of data, coupled with the rapid development of processor power and computer algorithms, has now made it possible to obtain and study vast amounts of data with relative ease.
It should be clear that machine learning is data science, which puts the importance of data in the center.
The field is full of technical jargon and can be intimidating to the uninitiated. We encounter many business leaders who have a hard time getting on the same page with their data science team. But that can’t be an excuse.
Machine learning has proven itself to be of extreme use if used purposefully. Therefore, business leaders must understand that machine learning is not merely about automation and doesn’t only belong to the data science team. If you think that way, you will likely miss valuable opportunities such as new business models, entirely new ways to monetize your offerings.
In the worst case, you might find yourself faced with disruption and not be able to respond.
We recommend that you think about machine learning not only as a powerful tool to find patterns in big data but consider it as a tremendous opportunity to take your organization to the next level.
Take the actions to incorporate machine learning as part of your strategic discussions.
Let us know how we can help.